 Jacob Tomlinson
Jacob Tomlinson
Originally published on the Dask blog on July 23rd, 2020.
Dask enables you to build up a graph of the computation you want to perform and then executes it in parallel for you. This is great for making best use of your computer’s hardware. It is also great when you want to expand beyond the limits of a single machine.
In this post we will cover:
Manual setup
Let’s dive in by covering the most straight forward way to setup a distributed Dask cluster.
Setup scheduler and workers
Imagine we have three computers, we will call them MachineA, MachineB and MachineC. Each of these machines has a functioning Python environment and we have installed Dask with conda install dask. If we want to pull them together into a Dask cluster we start by running a scheduler on MachineA.
$ dask-scheduler
distributed.scheduler - INFO - -----------------------------------------------
distributed.scheduler - INFO - Local Directory: /tmp/scheduler-btqf8ve1
distributed.scheduler - INFO - -----------------------------------------------
distributed.scheduler - INFO - Clear task state
distributed.scheduler - INFO - Scheduler at: tcp://MachineA:8786
distributed.scheduler - INFO - dashboard at: :8787
Next we need to start a worker process on both MachineB and MachineC.
$ dask-worker tcp://MachineA:8786
distributed.nanny - INFO - Start Nanny at: 'tcp://127.0.0.1:51224'
distributed.worker - INFO - Start worker at: tcp://127.0.0.1:51225
distributed.worker - INFO - Listening to: tcp://127.0.0.1:51225
distributed.worker - INFO - dashboard at: 127.0.0.1:51226
distributed.worker - INFO - Waiting to connect to: tcp://MachineA:8786
distributed.worker - INFO - -------------------------------------------------
distributed.worker - INFO - Threads: 4
distributed.worker - INFO - Memory: 8.00 GB
distributed.worker - INFO - Local Directory: /tmp/worker-h3wfwg7j
distributed.worker - INFO - -------------------------------------------------
distributed.worker - INFO - Registered to: tcp://MachineA:8786
distributed.worker - INFO - -------------------------------------------------
distributed.core - INFO - Starting established connection
If we start a worker on both of our two space machines Dask will autodetect the resources on the machine and make them available to the scheduler. In the example above the worker has detected 4 CPU cores and 8GB of RAM. Therefore our scheduler has access to a total of 8 cores and 16GB of RAM and it will use these resources to run through the computation graph as quickly as possible. If we add more workers on more machines then the amount of resources available to the scheduler increases and computation times should get faster.
Note: While the scheduler machine probably has the same resources as the other two these will not be used in the computation.
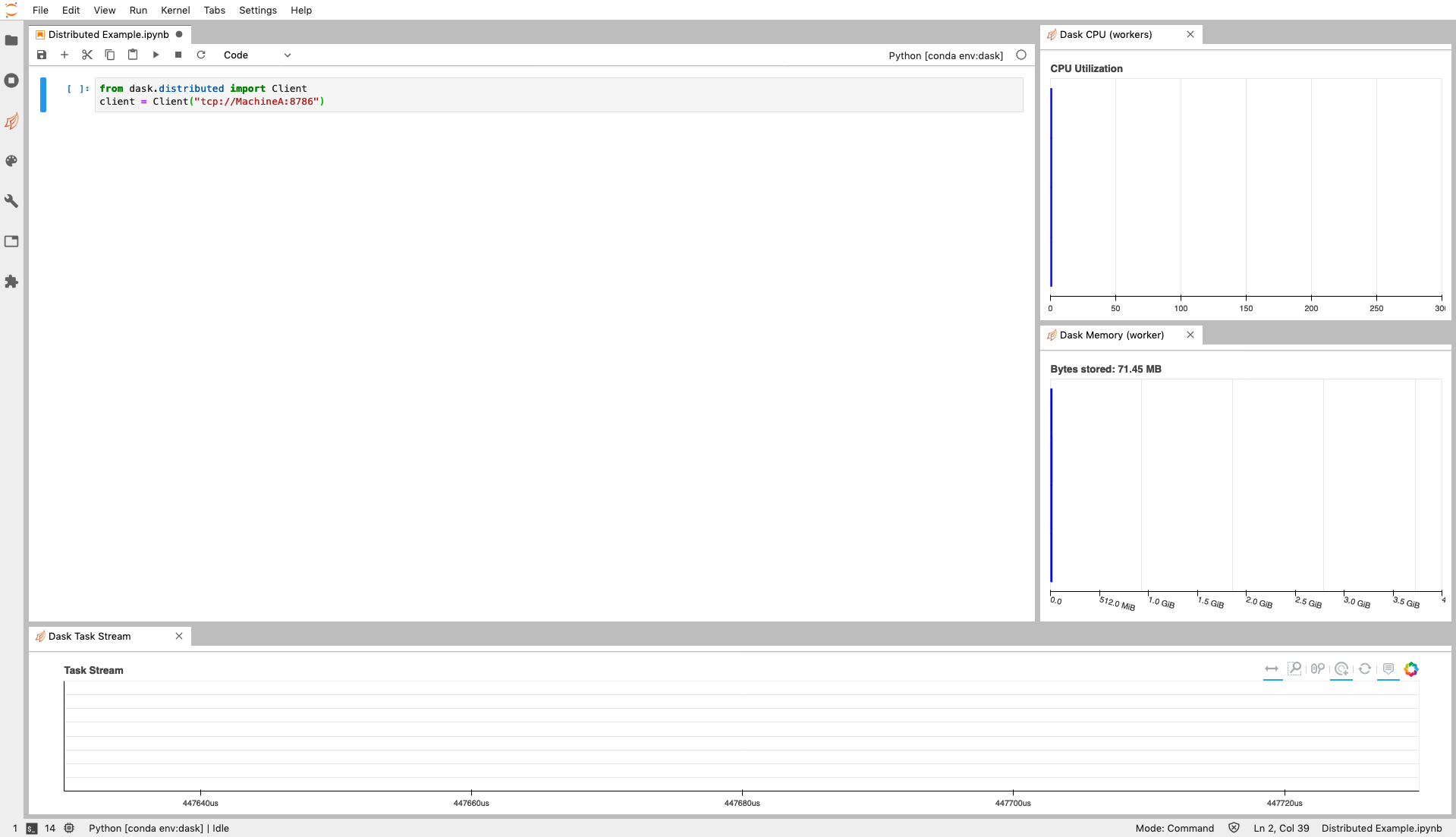
Lastly we need to connect to our scheduler from our Python session.
from dask.distributed import Client
client = Client("tcp://MachineA:8786")
Creating this Client object within the Python global namespace means that any Dask code you execute will detect this and hand the computation off to the scheduler which will then execute on the workers.
Accessing the dashboard
The Dask distributed scheduler also has a dashboard which can be opened in a web browser. As you can see in the output above the default location for this is on the scheduler machine at port 8787. So you should be able to navigate to http://MachineA:8787.
If you are using Jupyter Lab as your Python environment you are also able to open individual plots from the dashboard as windows in Jupyter Lab with the Dask Lab Extension.
Recap
In this minimal example we have installed Dask on some machines, ran a distributed scheduler on one of them and workers on the others. We then connected to our cluster from our Python session and opened the dashboard to keep an eye on the cluster.
What we haven’t covered is where these machines came from in the first place. In the rest of this post we will discuss the different ways that folks tend to run clusters out in the wild and give an overview of the various tools that exist to help you set up Dask clusters on a variety of infrastructure.
Cluster requirements
In order to run a Dask cluster you must be able to install Dask on a machine and start the scheduler and worker components. These machines need to be able to communicate via a network so that these components can speak to each other.
You also need to be able to access the scheduler from your Python session via a network in order to connect the Client and access the dashboard.
Lastly the Python environment in the Python session where you create your Client must match the Python environment where the workers are running. This is because Dask uses cloudpickle to serialize objects and send them to workers and to retrieve results. Therefore package versions must match in both locations.
We will need to bear these requirements in mind as we discuss the different platforms that folks generally want to run Dask on.
Cluster types
There are two “types” of clusters that I tend to see folks running. Fixed clusters and ephemeral clusters.
Fixed clusters
One common way of setting up a cluster is to run the scheduler and worker commands as described above, but leave them running indefinitely. For the purpose of this article I’ll refer to this as a “fixed cluster”. You may use something like systemd or supervisord to manage the processes and ensure they are always running on the machines. The Dask cluster can then be treated as a service.
In this paradigm once a cluster is set up folks may start their Python session, connect their client to this existing cluster, do some work and disconnect again. They might later come back to that cluster and run further work. The cluster will sit idle in the meantime.
It is also common in this paradigm for multiple users to share this single cluster, however this is not recommended as the Dask scheduler does not manage users or clients separately and work will be executed on a first come first served bases. Therefore we recommend that users use a cluster one at a time.
Ephemeral clusters
An ephemeral cluster is one which only exists for the duration of the work. In this case a user may SSH onto the machines, run the commands to set up the cluster, connect a client and perform work, then disconnect and exit the Dask processes. A basic way of doing this would be to create a bash script which calls ssh and sets up the cluster. You would run this script in the background while performing your work and then kill it once you are done. We will cover other implementations of this in the coming sections.
Ephemeral clusters allow you to leverage a bunch of machines but free them up again when you are done. This is especially useful when you are using a system like a cloud service or a batch scheduler where you have limited credits, or are charged for provisioned resources.
Adaptivity
Ephemeral clusters are also generally easier to scale as you will likely have an automated mechanism for starting workers. The Dask scheduler maintains an estimate of how long it expects the outstanding work will take to complete. If the scheduler has a mechanism for starting and stopping workers then it will scale up the workers in an attempt to complete all outstanding work within 5 seconds. This is referred to as adaptive mode.
The mechanisms for starting and stopping workers are added via plugins. Many of the implementations we are about to discuss include this logic.
Connectivity
Dask uses TCP to communicate between client, scheduler and workers by default. This means that all of these components must be on a TCP/IP network with open routes between the machines. Many connectivity problems step from firewalls or private networks blocking connections between certain components. An example of this would be running Dask on a cloud platform like AWS, but running the Python session and client on your laptop while sitting in a coffee shop using the free wifi. You must ensure you are able to route traffic between components, either by exposing the Dask cluster to the internet or by connecting your laptop to the private network via a VPN or tunnel.
There is also ongoing work to add support for UCX to Dask, which will allow it to make use of InfiniBand or NVLink networks where they are available.
Cluster Managers
In the following section we are going to cover a range of cluster manager implementations which are available within the Dask community.
In the Dask distributed codebase there is a Cluster superclass which can be subclassed to build various cluster managers for different platforms. Members of the community have taken this and built their own packages which enable creating a Dask cluster on a specific platform, for example Kubernetes.
The design of these classes is that you import the cluster manager into your Python session and instantiate it. The object then handles starting the scheduler and worker processes on the target platform. You can then create a Client object as usual from that cluster object to connect to it.
All of these cluster manager objects are ephemeral clusters, they only exist for the duration of the Python session and then will be cleaned up.
Local Cluster
Let’s start with one of the reference implementations of Cluster from the Dask distributed codebase LocalCluster.
from dask.distributed import LocalCluster, Client
cluster = LocalCluster()
client = Client(cluster)
This cluster manager starts a scheduler on your local machine, and then starts a worker for every CPU core that it finds on the machine.
SSH Cluster
Another reference implementation is SSHCluster. This is one of the most pure and simple ways of using multiple machines with Dask distributed and is very similar to our initial example in this blog post.
from dask.distributed import SSHCluster, Client
cluster = SSHCluster(["MachineA", "MachineB", "MachineC"])
client = Client(cluster)
The first argument here is a list of machines which we can SSH into and set up a Dask cluster on. The first machine in the list will be used as the scheduler and the rest as workers.
As the scheduler will likely use far less resources than the workers you may even want to run that locally and make use of all three remote machines as workers.
cluster = SSHCluster(["localhost", "MachineA", "MachineB", "MachineC"])
SpecCluster
The last implementation that is included in the core Dask distributed library is SpecCluster. This is actually another superclass and is designed to be subclassed by other developers when building cluster managers. However it goes further than Cluster in expecting the developer to provide a full specification for schedulers and workers as Python classes. There is also a superclass called ProcessInterface which is designed to be used when creating those scheduler and worker classes.
Having standard interfaces means a more consistent experience for users. Many of the cluster manager we will cover next use SpecCluster.
Dask Kubernetes
Dask Kubernetes provides a cluster manager for Kubernetes called KubeCluster.
Kubernetes provides high level APIs and abstract concepts for scheduling linux containers on a cluster of machines. It provides abstracted concepts for processes, containers, networks, storage, etc to empower better use of data centre scale resources.
As a Dask user it generally doesn’t matter to you how your cluster is set up. But if you’ve been given access to a Kubernetes cluster by your organisation or institution you will need to understand those concepts in order to schedule your work on it.
The KubeCluster cluster manager further abstracts away those concepts into the Dask terms we are familiar with.
from dask.distributed import Client
from dask_kubernetes import KubeCluster
cluster = KubeCluster(**cluster_specific_kwargs)
client = Client(cluster)
In order for this code to work you will need to have configured your Kubernetes credentials, in the same way that for the SSH example you will need to configure your keys.
Your client will also need to be able to access the Dask scheduler, and you probably want to be able to open the dashboard in your browser. However Kubernetes uses an overlay network which means that the IP addresses assigned to the scheduler and workers are only routable within the cluster. This is fine for them talking to each other but means you wont be able to get in from the outside.
One way around this is to ensure your Python session is also running inside the Kubernetes cluster. A popular way of setting up an interactive Python environment on Kubernetes is with Zero to Jupyter Hub, which gives you access to Jupyter notebooks running within the Kubernetes cluster.
The alternative is exposing your scheduler to the external network. You can do this by exposing the Kubernetes Service object associated with the scheduler or by setting up and configuring an Ingress component for your Kubernetes cluster. Both of these options require some knowledge of Kubernetes.
Dask Helm chart
Another option for running Dask on a Kubernetes cluster is using the Dask Helm Chart.
This is an example of a fixed cluster setup. Helm is a way of installing specific resources on a Kubernetes cluster, similar to a package manager like apt or yum. The Dask Helm chart includes a Jupyter notebook, a Dask scheduler and three Dask workers. The workers can be scaled manually by interacting with the Kubernetes API but not adaptively by the Dask scheduler itself.
This feels like a different approach to what we’ve seen so far. It gives you a Dask cluster which is always available, and a Jupyter notebook to drive the cluster from. You then have to take your work to the cluster’s Jupyter session rather than spawning a cluster from your existing work place.
One benefit of this approach is that because the Jupyter notebook has been set up as part of the cluster it already has the Lab Extension installed and also has been pre-configured with the location of the Dask cluster. So unlike previous examples where you need to either give the Client the address of the scheduler or a Cluster object, in this instance it will auto-detect the cluster from environment variables that are set by the Helm chart.
from dask.distributed import Client
client = Client() # The address is loaded from an environment variable
Note: If you call Client without any arguments in other situations where the scheduler location has not been configured it will automatically create a LocalCluster object and use that.
Dask Jobqueue
Dask Jobqueue is a set of cluster managers aimed at HPC users.
When working as a researcher or academic with access to an HPC or Supercomputer you likely have to submit work to that machine via some kind of job queueing system. This is often in the form of a bash script which contains metadata about how much resource you need on the machine and the commands you want to run.
Dask Jobqueue has cluster manager objects for PBS, Slurm, and SGE. When creating these cluster managers they will construct scripts for the batch scheduler based on your arguments and submit them using your default credentials.
from dask.distributed import Client
from dask_jobqueue import PBSCluster
cluster = PBSCluster(**cluster_specific_kwargs)
client = Client(cluster)
As batch systems like these often have a long wait time you may not immediately get access to your cluster object and scaling can be slow. Depending on the queueing policies it may be best to think of this as a fixed sized cluster. However if you have a responsive interactive queue then you can use this like any other autoscaling cluster manager.
Again it is expected that your Python session is able to connect to the IP address of the scheduler. This may vary depending on your HPC centre setup as to how you can ensure this.
Dask Yarn
Dask Yarn is a cluster manager for traditional Hadoop systems.
Hadoop is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is a common piece of infrastrcture in Java/Scala ecosystems for processing large volumes of data. However you can also use the scheduling functionality called YARN to schedule Dask workers and leverage the underlying hardware resources.
from dask.distributed import Client
from dask_yarn import YarnCluster
cluster = YarnCluster(**cluster_specific_kwargs)
client = Client(cluster)
Dask Yarn is only intended to be used from a Hadoop edge node which will have access to the internal network of the Hadoop cluster.
Dask Cloudprovider
Dask Cloudprovider is a collection of cluster managers for leveraging cloud native APIs.
Cloud providers such as Amazon, Microsoft and Google have many APIs available for building and running various types of infrastructure. These range from traditional virtual servers running linux or Windows to higher level APIs that can execute small snippets of code on demand. They have batch systems, Hadoop systems, machine learning systems and more.
The ideal scenario for running Dask on a cloud provider would be a service which would allow you to run the scheduler and worker with specified Python environments and then connect to them securely from the outside. Such a service doesn’t quite exist, but similar things do to varying degrees.
One example is AWS Fargate which is a managed container platform. You can run Docker containers on demand which each have a unique IP address which can be public or private. This means we can run Dask scheduler and worker processes within a Dask container and connect to them from our Python session. This service is billed per second for the requested resources, so makes most sense as an ephemeral service which has no cost when you aren’t using it.
from dask.distributed import Client
from dask_cloudprovider import FargateCluster
cluster = FargateCluster(**cluster_specific_kwargs)
client = Client(cluster)
This cluster manager uses your AWS credentials to authenticate and request AWS resources on Fargate, and then connects your local session to the Dask cluster running on the cloud.
There are even higher level services such as AWS Lambda or Google Cloud Functions which allow you to execute code on demand and you are billed for the execution time of the code. These are referred to as “serverless” services as the servers are totally abstracted away. This would be perfect for out Dask cluster as you could submit the scheduler and workers as the code to run. However when running these cloud functions it is not possible to get a network connection between them as they do not have routable IP addresses, so there is no way to set up a Dask cluster made of these executing functions. Maybe one day!
Dask Gateway
Dask Gateway is a central service for managing Dask clusters. It provides a secure API which multiple users can communicate with to request Dask servers. It can spawn Dask clusters on Kubernetes, Yarn or batch systems.
This tool is targeted at IT administrators who want to enable their users to create Dask clusters, but want to maintain some centralized control instead of each user creating their own thing. This can also be useful for tracking Dask usage and setting per user limits.
from dask.distributed import Client
from dask_gateway import GatewayCluster
cluster = GatewayCluster(**cluster_specific_kwargs)
client = Client(cluster)
For each user the commands for creating and using a gateway cluster are the same. It is down to the administrator to setup and manage the gateway server and configure authentication via kerberos or Jupyter Hub. They should also provide configuration to their users so that Dask Gateway knows how to connect to the gateway server. In a large organisation or institution the IT department also likely provisions the machines that staff are using, and so should be able to drop configuration files onto users computers.
Local CUDA Cluster
The last cluster manager I’m going to cover is LocalCUDACluster from the Dask CUDA package.
This is slightly different than the other cluster managers in that it is constructing a Dask cluster which is specifically optimised for a single piece of hardware. In this case it is targeting machines with GPUs ranging from your laptop with an onboard NVIDIA GPU to an NVIDIA DGX-2 with multiple GPUs running in your datacentre.
The cluster manager closely follows the LocalCluster in that is creates resources locally on the current machine, but instead of creating one worker per CPU core it creates one per GPU. It also changes some of the configuration defaults to ensure good performance of GPU workloads.
from dask.distributed import Client
from dask_cuda import LocalCUDACluster
cluster = LocalCUDACluster(**cluster_specific_kwargs)
client = Client(cluster)
This package also has an alternative Dask worker bash command called dask-cuda-worker which also modified the defaults of the Dask worker to ensure it is optimised for GPU work.
Future
Now that we have laid out the current state of the Dask distributed cluster ecosystem let’s discuss where we could go next.
As shown at the beginning a Dask cluster is a combination of scheduler, workers and client which enable distributed execution of Python functions. Setting up your own cluster on your own machines is straight forward, but there is such a variety of ways to provision infrastructure that we now have a number of ways of automating this.
This variation opens up a number of questions about how we can improve things.
Do we need more fixed cluster options?
While covering the various cluster managers we only covered one fixed cluster implementation, the Helm chart. Is there a requirement for more fixed clusters? Examples may be CloudFormation or Terraform templates which follow the same structure as the Helm chart, providing a Jupyter service, Dask scheduler and fixed number of workers.
Can we bridge some gaps?
Could the Dask Kubernetes cluster manager connect to an existing cluster that was built using the Helm chart to then perform adaptive scaling? I’ve been asked this a lot but it is currently unclear how to get to this position. The cluster manager and Helm chart use different Kubernetes resources to achieve the same goal, so some unification would be needed before this is possible.
Are ephemeral clusters too ephemeral?
Many of the cluster managers only exist for the duration of the Python session. However some like the YarnCluster allow you to disconnect and reconnect from the cluster. This allows you to treat a YARN cluster more like a fixed cluster.
In other circumstances the Python session may have a timeout or limit and may be killed before the Dask cluster can complete its work. Would there be benefit to letting the Dask cluster continue to exist? With the Python session cleared up the client and futures will also be garbage collected. So perhaps not.
Can we manage conda environments better?
Currently it is the responsibility of the person creating the cluster to ensure that the worker’s conda environment matches the one where the Client is going to be created. On fixed clusters this can be easier as the Python/Jupyter environment can be provided within the same set of systems. However on ephemeral clusters where you may be reaching into a cloud or batch system they may not match your laptop’s environment for example.
Perhaps there could be integration between workers and conda to create dynamic environments on the fly. Exploring the performance impact of this would be interesting.
Another option could be enabling users to start a remote Jupyter kernel on a worker. They wouldn’t have access to the same filesystem, but they would share a conda environment.